🐰详细讲解数据库面试常见问题,包含索引、锁、事务等内容🐰
数据库面试总结
1. 架构
1. RDBMS
- 程序实例
- 存储管理
- 缓存机制
- SQL解析
- 日志管理
- 权限划分
- 索引管理
- 锁管理
- 存储(文件系统)
2. 索引
- 为什么要使用索引:避免全表扫描/快速查询数据
- 什么样的信息能成为索引:主键、唯一键
- 索引的数据结构
- 建立二叉查找树进行二分查找
- 建立B-Tree结构进行查找
- 建立B+-Tree结构进行查找
- 建立Hash结构进行查找
1. 优化索引
-
二叉查找树
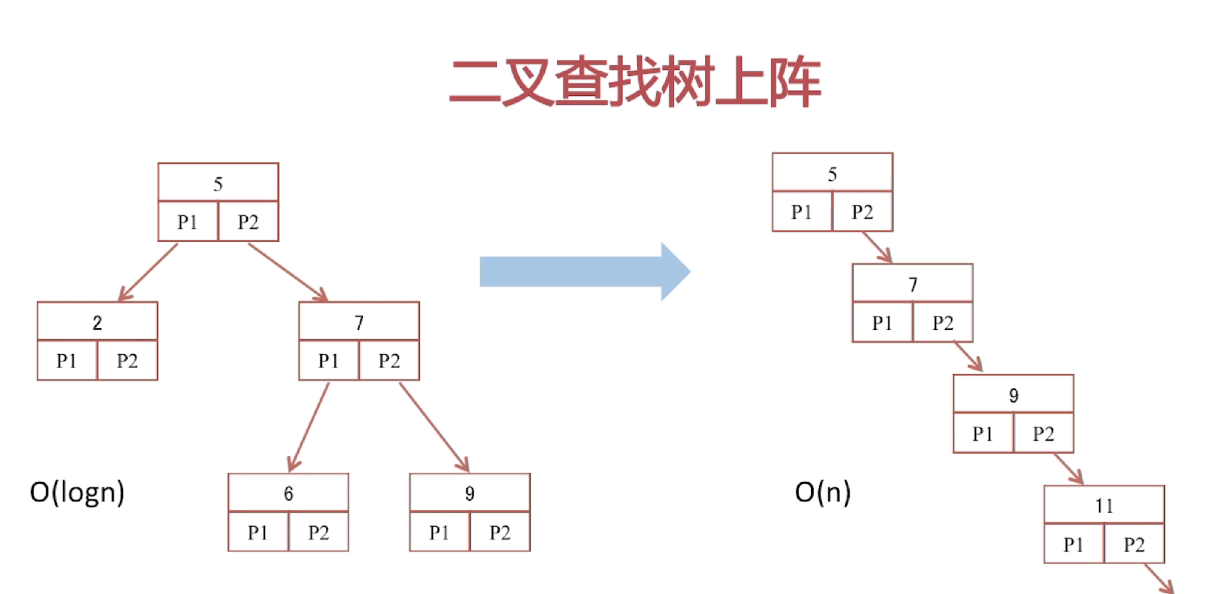
-
B-Tree(logn)
- 根节点至少包括两个孩子
- 树中每个节点最多含有m个孩子(m>=2)
- 除根节点和叶节点外,其他每个节点至少有ceil(m/2)个孩子
- 所有叶子节点都位于同一层
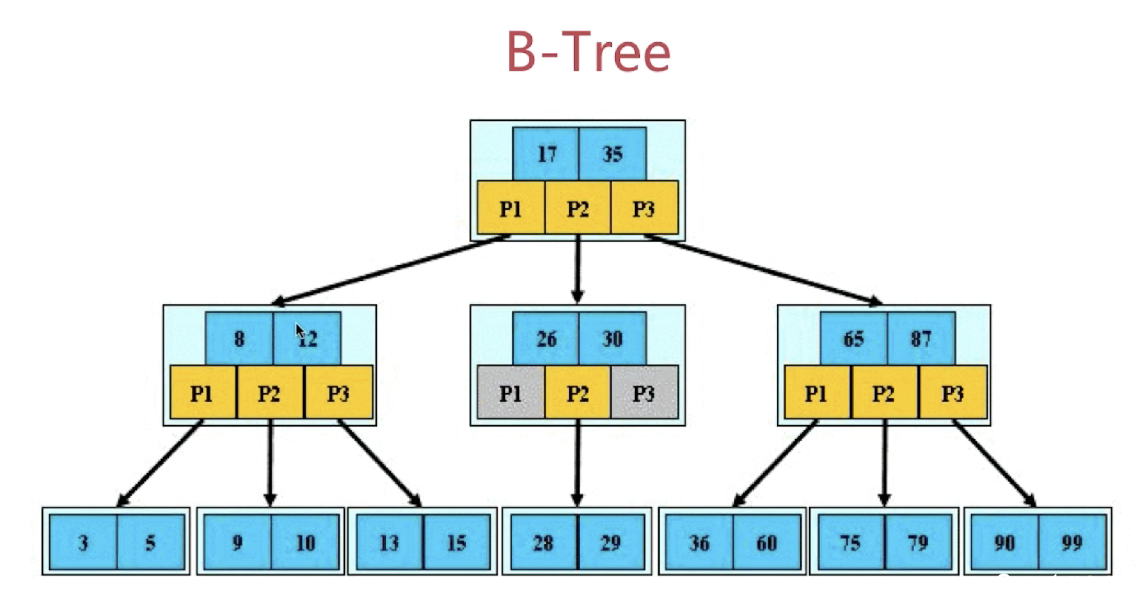
-
B+树
- 定义基本与B树相同
- 除了非叶子节点的指针必须与叶子结点数相同
- 非叶子节点的子树指针P[i],指向关键字符[K[i],K[i+1]]的子树
- 非叶子节点仅用来索引,数据都保存在叶子结点中
- 所有叶子节点均有一个链指针指向下一个叶子结点
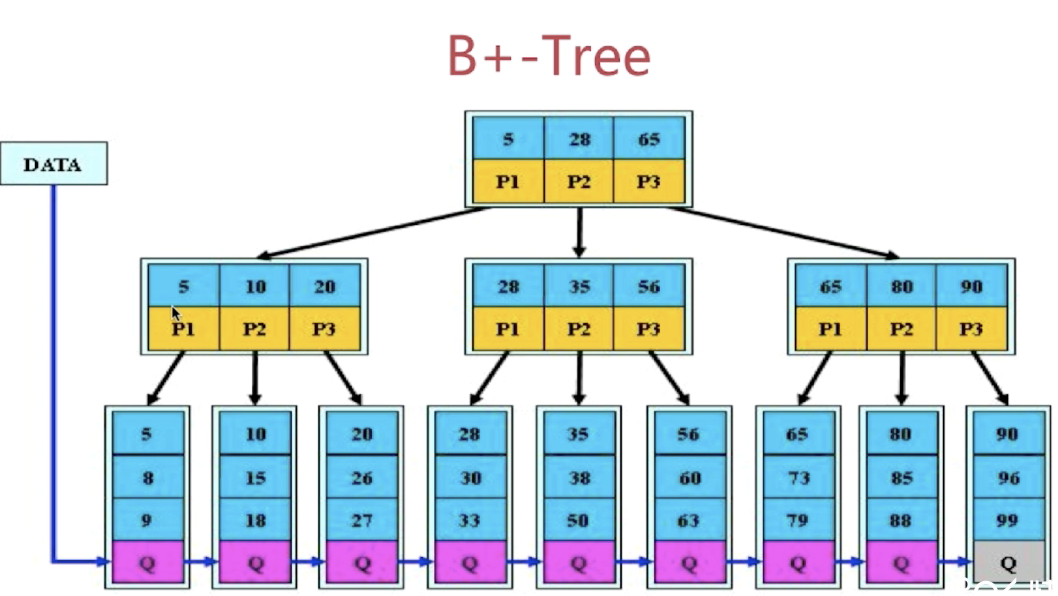
-
为什么B+树更适合用来做存储索引
- B+树的磁盘读写代价更低
- B+树的查询效率更加稳定
- B+树更有利于对数据库的扫描
2. Hash索引
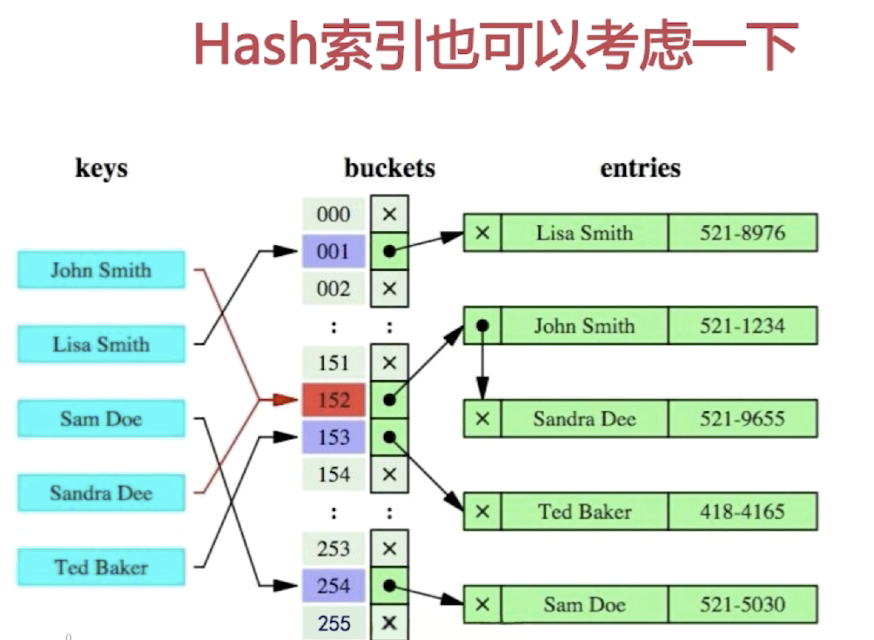
缺点:
- 仅仅能满足“=”,“IN",不能使用范围查询
- 无法被用来避免数据的排序操作
- 不能利用部分索引键查询
- 不能避免表扫描
- 遇到大量Hash值相等的情况后性能并不一定就会比B-Tree索引高
3. BitMap索引(了解)
- 位图索引
4. 密集索引与稀疏索引的区别
- 密集索引文件中的每个搜索码值都对应一个索引值
- 系数索引文件只为索引码的某些值建立索引项
- 对于InnoDB
- 若一个主键被定义,则该主键作为密集索引
- 若没有主键被定义,该表的第一个唯一非空索引则作为密集索引
- 若没有,innodb内部会生成一个隐藏主键(密集索引)
- 非主键索引存储相关键位和其对应的主键值,包含两次查找
- 索引和数据是存在一起的
- 对于MyISAM
- 都是稀疏索引
- 索引和数据是分开的
5. 问题回顾与总结
- 为什么要使用索引
- 什么样的信息能成为索引
- 索引的数据结构
- 密集索引和系数索引的区别
6. 一些衍生问题
6.1 如何定位并优化慢查询Sql
- 根据慢日志定位慢查询sql
- 使用explain等工具分析sql
- using filesort:文件排序 不能使用索引
- using temporary:使用临时表
- 修改sql或者尽量让sql走索引
6.2 联合索引的最左匹配原则的成因
- MySQL会一直向右匹配到范围查询(>、<、between、like)就停止匹配
a = 1 and b = 2 and c > 3 and d = 4
如果遇到(a,b,c,d)这样的,到c就停止了
6.3 索引是建立的越多越好吗
- 否。数据量小的表不需要建立索引,建立或增加额外的索引开销
- 数据变更需要维护索引,因此更多的索引意味着更多的维护成本
- 更多的索引意味着也需要更多的空间
3. 锁
3.1 常见问题
- MyISAM与InnoDB关于锁方面的区别是什么
- 数据库事务的四大特性
- 事务隔离级别以及各2级别下的并发访问问题
- InnoDB可重复读隔离级别下如何避免幻读
- RC、RR级别下的InnoDB的非阻塞读如何实现
1. MyISAM与InnoDB关于锁方面的区别是什么
- MyISAM默认用的是表级锁,不支持行级锁
- InnoDB默认用的是行级锁,也支持表级锁
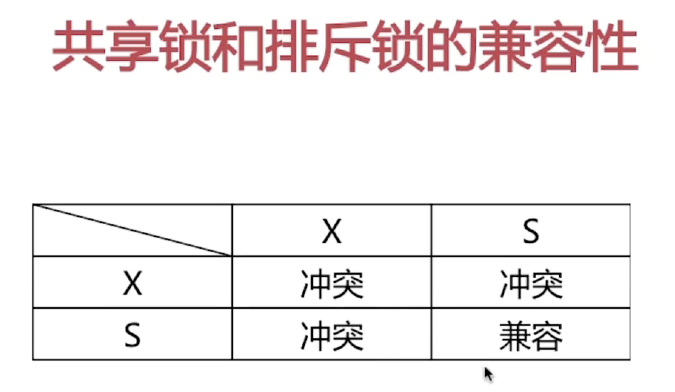
- 写锁 又叫 排它锁
- 读锁 又叫 共享锁
- 先读再写不会被锁
- 先写再读会被锁
2. MyISAM适合的场景
- 频繁执行全表count语句
- 对数据进行增删改的频率不搞,查询非常频繁
- 没有事务
3. InnoDB适合的场景
- 数据增删改查都相当频繁
- 可靠性要求比较高,要求支持事务
3.2 数据库锁的分类
- 按锁的粒度分化,可分为表级锁、行级锁、页级锁
- 按锁的级别划分,可分为共享锁、排它锁
- 按枷锁方式划分,课分为自动锁、显式锁
- 按操作划分,可分为DML锁、DDL锁
- 按使用方式划分,可分为乐观锁、悲观锁
1. 乐观锁的实现方式
- 基于时间戳
- 基于版本号(写SQL语句的时候先检查version)
3.3 数据库事务的四大特性
- 原子性(Atomic):发生错误回滚
- 一致性(Consistency)
- 隔离性(Isolation):一个事务的执行不应该影响到其他事务
- 持久性(Durability):redo log
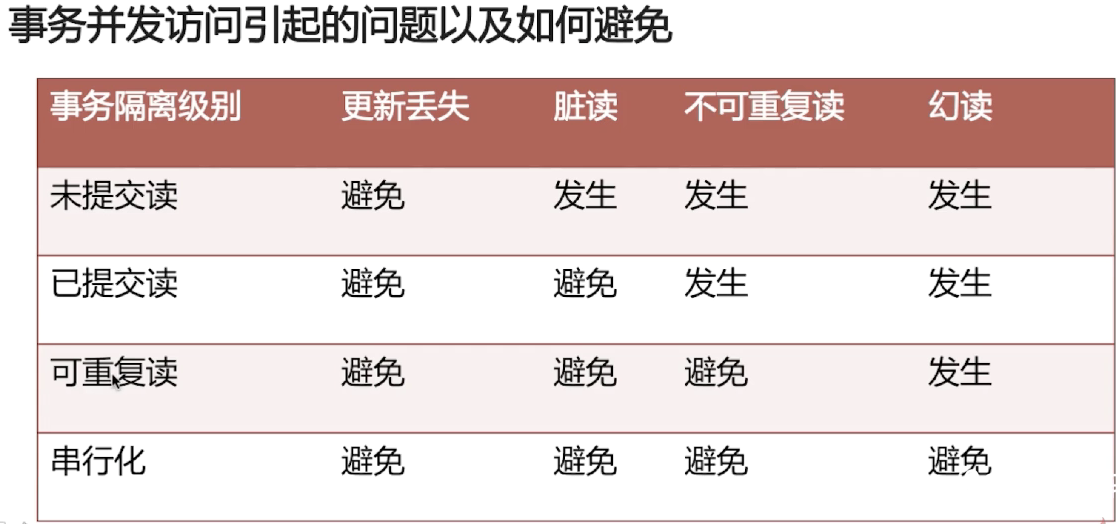
3.4 事务隔离级别以及各级别下的并发访问问题
- 更新丢失:mysql所有事务隔离级别在数据库层面上均可避免
- 脏读:一个事务读到另外一个事务未提交的数据:READ——COMMITTED事务隔离级别以上可避免(MyISAM默认)
- 只能读到其他事务提交的级别,就不会造成问题了
- 不可重复读:REPEATABLE-READ事务隔离级别以上可避免(InnoDB默认)
- 幻读:另外一个事务对同一个数据库进行了插入或者删除操作:SERIALIZABLE事务隔离级别可避免
3.5 InnoDB课重复读隔离级别下如何避免幻读
- 表象:快照读(非阻塞读)——伪MVCC
- 当前读:update、delete、insert、select...lock in share mode
- 快照读:不加锁的非阻塞读、select
- 再次调用快照读会出问题
- 内在:next-key锁(行锁+gap锁)(搞不懂)
- 在Serializable下 是用的这个
3.6 RC、RR级别下的InnoDB的非阻塞读如何实现
- 数据行里的DB_TRX_ID、DB_ROLL_PTR、DB_ROW_ID字段
- 从 undo日志 里恢复
- read view
4. 语法
- GROUP BY
- HAVING
- 统计相关:COUNT、SUM、MAX、MIN、AVG
1. GROUP BY(分组)
- 满足 “select字句中的列名必须为分组列或者列函数”
- 列函数对于group by字句定义的每个组各返回一个结果
- 如果用group by,那么你的Select语句中选出的列要么是你group by里用到的列,要么就是带有之前我们说的如sum min等列函数的列,如果带上其他的,会报错。
2. HAVING(过滤)
- 通常与GROUP BY字句一起使用
- WHERE过滤行,HAVING过滤组
- 出现在同一行sql的顺序:WHERE>GROUP BY>HAVING
3.自己多练
5 MyISAM与InnoDB区别
- InnoDB支持事务,MyISAM不支持,对于InnoDB每一条SQL语言都默认封装成事务,自动提交,这样会影响速度,所以最好把多条SQL语言放在begin和commit之间,组成一个事务;
- InnoDB支持外键,而MyISAM不支持。对一个包含外键的InnoDB表转为MYISAM会失败;
- InnoDB是聚集索引,使用B+Tree作为索引结构,数据文件是和(主键)索引绑在一起的(表数据文件本身就是按B+Tree组织的一个索引结构),必须要有主键,通过主键索引效率很高。但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到数据。因此,主键不应该过大,因为主键太大,其他索引也都会很大。
- InnoDB不保存表的具体行数,执行select count(*) from table时需要全表扫描。而MyISAM用一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可,速度很快(注意不能加有任何WHERE条件)
- Innodb不支持全文索引,而MyISAM支持全文索引,在涉及全文索引领域的查询效率上MyISAM速度更快高;PS:5.7以后的InnoDB支持全文索引了
- MyISAM表格可以被压缩后进行查询操作
- InnoDB支持表、行(默认)级锁,而MyISAM支持表级锁
- InnoDB表必须有主键(用户没有指定的话会自己找或生产一个主键),而Myisam可以没有
- Innodb存储文件有frm、ibd,而Myisam是frm、MYD、MYI
- Innodb:frm是表定义文件,ibd是数据文件
- Myisam:frm是表定义文件,myd是数据文件,myi是索引文件
6. SQL语句的优化
1. 定位慢SQL语句
-
好慢询可以帮我们找到执行慢的 SQL,在使用前,我们需要先看下慢查询是否已经开启,使用下面这条命令即可:
mysql > show variables like '%slow_query_log'; -
我们能看到 slow_query_log=OFF,也就是说慢查询日志此时是关上的。我们可以把慢查询日志打开,注意设置变量值的时候需要使用 global,否则会报错
mysql > set global slow_query_log='ON'; mysql > set global long_query_time = 3;
2. 使用EXPLAIN
EXPLAIN 可以帮助我们了解数据表的读取顺序、SELECT 子句的类型、数据表的访问类型、可使用的索引、实际使用的索引、使用的索引长度、上一个表的连接匹配条件、被优化器查询的行的数量以及额外的信息(比如是否使用了外部排序,是否使用了临时表等)等。
EXPLAIN SELECT comment_id, comment_text, user_id FROM product_comment WHERE comment_id = 500000;
3. 使用PROFILE
- SHOW PROFILE 相比 EXPLAIN 能看到更进一步的执行解析,包括 SQL 都做了什么、所花费的时间等。默认情况下,profiling 是关闭的,我们可以在会话级别开启这个功能。
mysql > set profiling = 'ON';
mysql > show profiles;
- 不过 SHOW PROFILE 命令将被弃用,我们可以从 information_schema 中的 profiling 数据表进行查看。