🌈最近在学习消息中间件,由于大数据端天生靠近数据,所以在很多场景下,会需要对日志等文件进行分析
🎊那么这一系列,我们使用Python语言对常用的消息中间件进行一次整合
🎉看看如何将nginx、kafka、zookeeper、redis、logstash一起,使用python语言搭建一个日志报警系统吧
1. 常用消息中间件比较
1.1 常用消息中间件介绍
- Redis
- RabbitMQ
- RocketMQ
- ZeroMQ
- Kafka
1.2 常用消息中间件对比
- 实现语言
- 对外接口
- 持久化策略
- 消息处理模式
- 时序保证
| 消息中间件 | 实现语言 | 持久化 | 消息处理模式 | 时序保证 |
|---|---|---|---|---|
| Redis | C | 支持磁盘 | Push-Pull Pub-Sub | 有序 |
| RabbitMQ | Erlang | 磁盘 | Push | 单消费者有序 |
| RocketMQ | Java | 磁盘 | Puch-Pull | 同队列有序 |
| Kafka | Scala | 磁盘 | Pull | 单Paritition有序 |
2. 消息中间件常见概念
2.1 消息中间件中的各种概念和角色
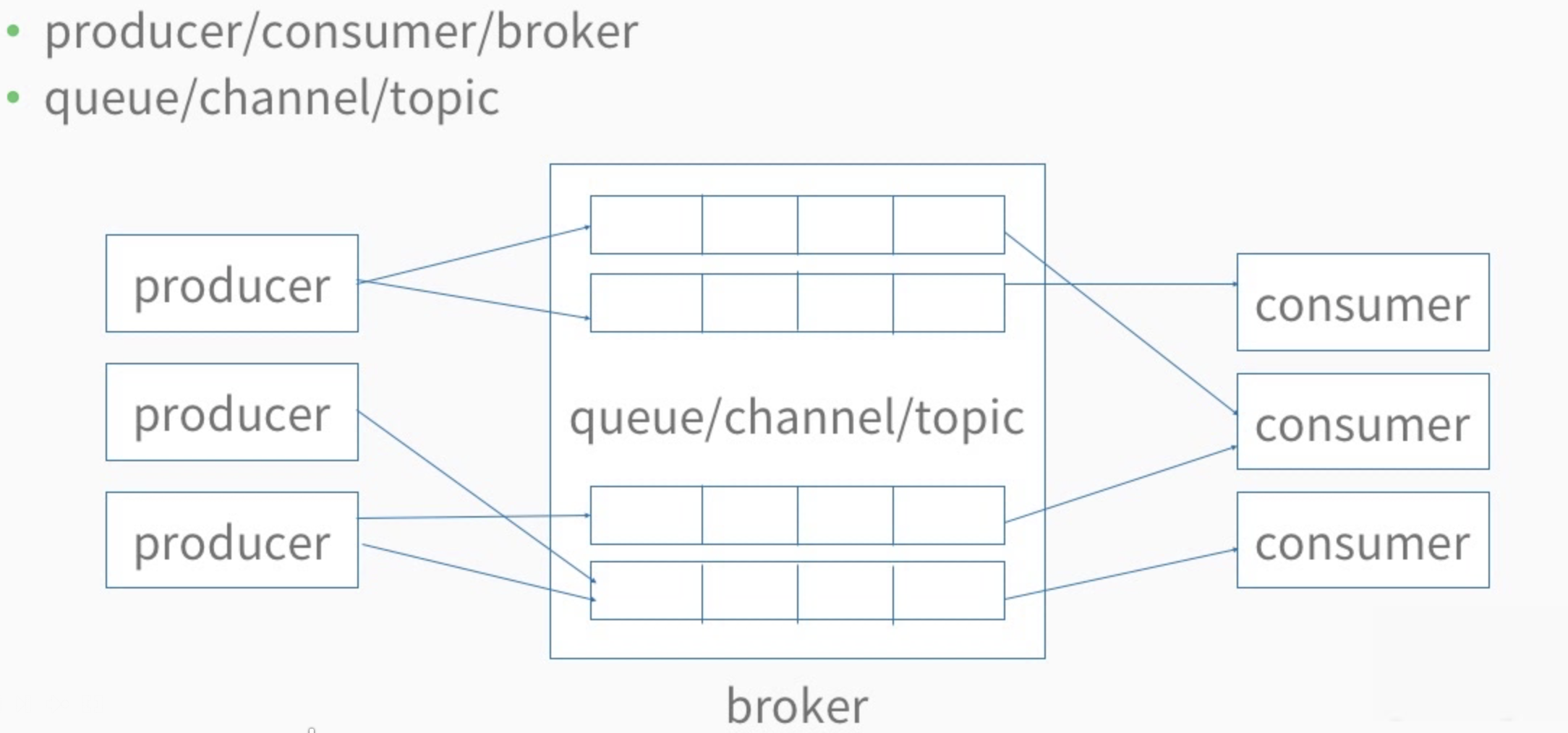
- Producer/borker/cunsumer
- Queue/channel/topic
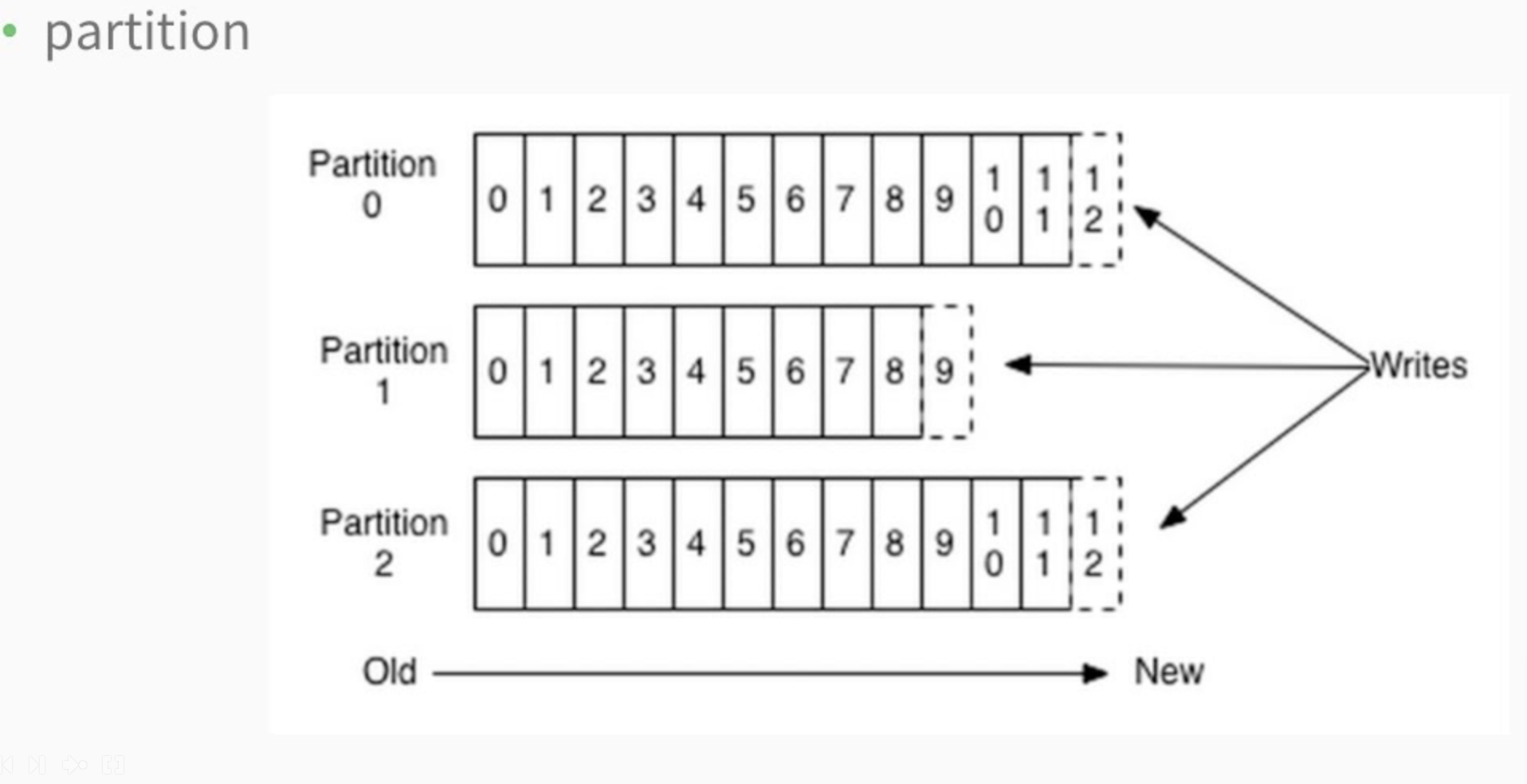
- Partition
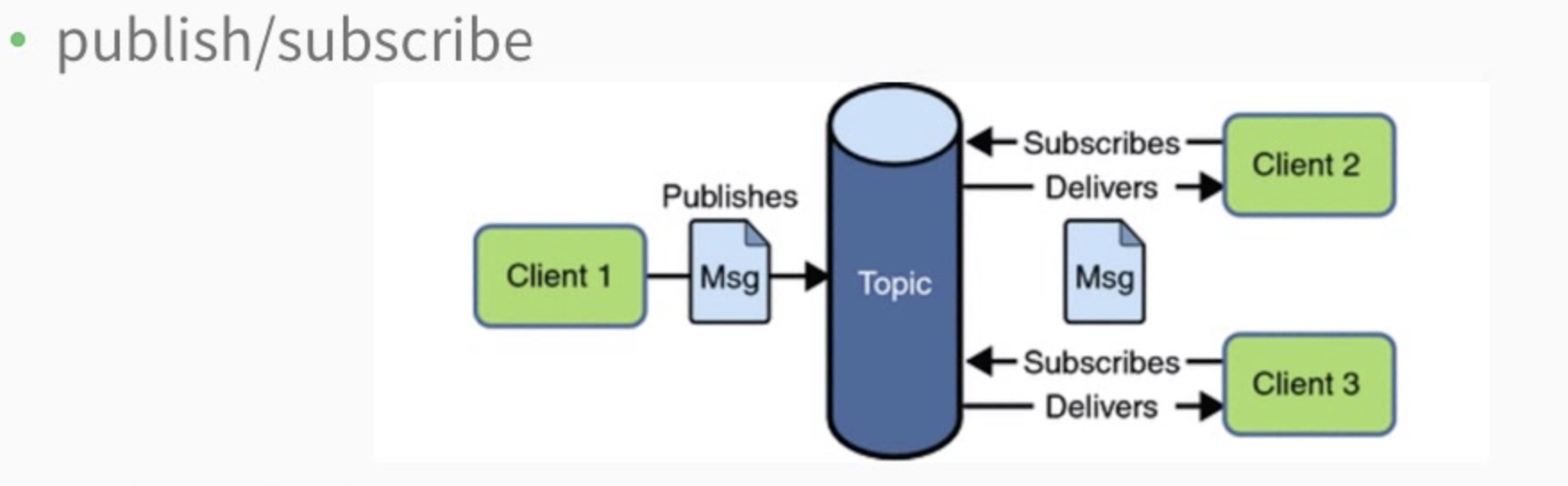
- Publish/subscribe
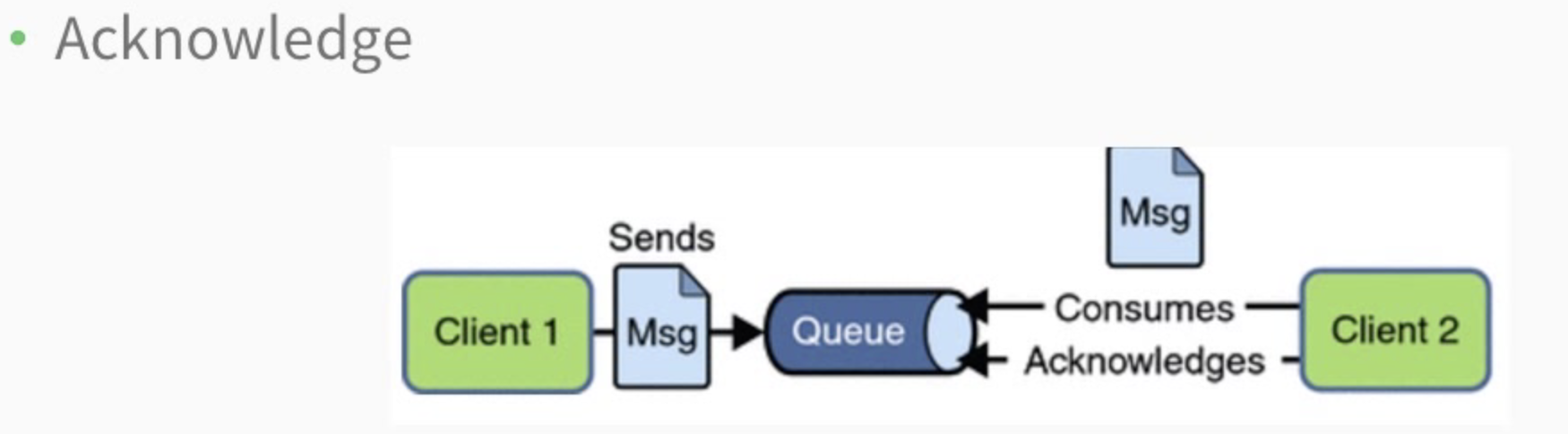
- Acknowledge
2.2 生产者
2.3 Partition
- 一个topic可以分为多个partition
2.4 订阅
2.5 消息确认机制
- 只有经过用户确认的消息才会从queue中去除
3. Redis
3.1 Redis简介
Redis关键词
- Key-value
- 高性能
- 缓存
- C开发
- 五大数据结构
- lua扩展
3.2 Redis常见应用场景
-
String
- 缓存二进制对象,比如图片、序列化对象等
- 计数器,比如文章访问量统计
- 位运算,节约内存
-
List
- 获取最新的N条数据
- 消息队列
- 实时分析系统,比如服务器监控程序
-
Hash
-
类似Python中的Dict
-
存储具有多个属性的对象
-
比如用户的年龄、姓名、性别、积分
-
-
Set
- 集合操作,比如通过交集实现共同关注,共同好友
- 存储无序不重复数据,比如存储文章标签
-
Sorted Set
- TopN排序,比如排行榜
- 范围查找,比如判断ip地址所在地
- 优先级队列
- 过期项目处理
-
Pub Sub
- 实时消息系统
- 比如即时聊天,群聊
3.3 Redis安装与默认配置
3.3.1Redis服务器默认配置
- 端口号:port=6379
- IP地址 bind=0.0.0.0
- 数据库存放位置 dir=./
- 数据库名字 dbfilename=dump.rdb
- 守护进程模式 daemonize=no
3.3.2 Redis服务器配置文件
-
Redis服务器启用配置文件:运行
redis-server name.conf -
查看redis服务器所有选项配置:运行
redis-cli config get '*' -
查看redis服务器某个配置选项:运行
redis-cli config get xxx(e.g: bind)
3.3.3 常见参数
- --daemonize
- 含义:是否以守护进程的形式启动(后台启动)
- 用法:daemonize yes|no
- 默认值:no
- 实例:daemonize yes
- --bind
- 含义:redis监听的ip地址
- 用法:bind ip地址
- 默认值:127.0.0.1
- 实例:bind 0.0.0.0(监听所有)
- --port(一般不改)
- 含义:redis监听的端口号
- 用法:port 端口号
- 默认值:6379
- 实例:port 6380
- --dir
- 含义:redis持久化文件存放目录
- 用法:dir 文件路径
- 默认值:./
- 实例:dir /mnt/redis/data/
- --dbfilename
- 含义:redis持久化文件文件名
- 用法:dbfilename 文件名
- 默认值:dump.rdb
- 实例:dbfilename xxxx.rdb(e.g. user.rdb)
- --unixsocket(效率高于socket套接字)
- 含义:redis监听的unix套接字地址
- 用法:unixsocket文件地址
- 默认值:空
- 实例:unixsocket /tmp/redis.sock
3.4 Redis常见操作和命令
首先使用redis-server启动redis服务,然后使用redis-cli进入命令行界面
3.4.1 Redis常用命令讲解
- 测试客户端与服务器连接是否正常:PING
- 获得符合规则的键名列表:KEYS pattern
- 判断一个键是否存在:EXISTS key
- 删除一个键:DEL key
- 获取键的类型:TYPE key
- 清空当前数据库所有数据:FLUSHDB
- 设置一个键的生育生存时间:EXPIRE key seconds
- 返回一个键的生育生存时间:TTL key
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> keys *
1) "1558695101775_0.7258740928094547"
2) "1558693978601_0.21519364815403463"
3) "1558695158141_0.8666190807031027"
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> keys *
(empty list or set)
127.0.0.1:6379> set foo bar
OK
127.0.0.1:6379> keys foo
1) "foo"
127.0.0.1:6379> type foo
string
127.0.0.1:6379> exists foo
(integer) 1
127.0.0.1:6379> del foo
(integer) 1
127.0.0.1:6379> keys *
(empty list or set)
127.0.0.1:6379> set foo bar
OK
127.0.0.1:6379> expire foo 60
(integer) 1
127.0.0.1:6379> ttl foo
(integer) 58
127.0.0.1:6379> ttl foo
(integer) -2
3.4.2 Redis常用命令之String
- SET
- GET
- INCR(递增一个值为整数的string)
- MSET(批量设置)
- MGET(批量获取)
127.0.0.1:6379> set foo barstring
OK
127.0.0.1:6379> get foo
"barstring"
127.0.0.1:6379> get ffo
(nil)
127.0.0.1:6379> mset foo1 bar1 foo2 bar2 foo3 bar3
OK
127.0.0.1:6379> mget foo1 foo2 foo3
1) "bar1"
2) "bar2"
3) "bar3"
127.0.0.1:6379> set num 1
OK
127.0.0.1:6379> incr num
(integer) 2
127.0.0.1:6379> get num
"2"
3.4.3 Redis常用命令讲解之Hash
- HSET
- HGET
- HMSET
- HMGET
- HGETALL
- HDEL
127.0.0.1:6379> hset user name 3zz
(integer) 1
127.0.0.1:6379> hset user sex man
(integer) 1
127.0.0.1:6379> hget user name
"3zz"
127.0.0.1:6379> hgetall user
1) "name"
2) "3zz"
3) "sex"
4) "man"
127.0.0.1:6379> hdel user name
(integer) 1
127.0.0.1:6379> hgetall user
1) "sex"
2) "man"
127.0.0.1:6379> del user
(integer) 1
127.0.0.1:6379> exists user
(integer) 0
3.4.4 Redis常用命令讲解之List
- LPUSH(从左侧放入)
- RPUSH(从右侧放入)
- LPOP(从左侧拿出)
- RPOP(从右侧拿出)
- BRPOP(有数据则返回,没有就一直等待直到有数据)
- LLEN(返回长度)
- LRANGE(返回从索引start到end两端的元素,左右都闭)
- RPOPLPUSH(先右拿出 左放入)
127.0.0.1:6379> lpush list0 a
(integer) 1
127.0.0.1:6379> lpush list0 b c
(integer) 4
127.0.0.1:6379> lrange list0 0 -1
1) "c"
2) "b"
3) "a"
127.0.0.1:6379> rpush list0 d e
(integer) 5
127.0.0.1:6379> lrange list0 0 -1
1) "c"
2) "b"
3) "a"
4) "d"
5) "e"
127.0.0.1:6379> llen list0
(integer) 5
127.0.0.1:6379> rpoplpush list0 list1
"e"
127.0.0.1:6379> lrange list1 0 -1
1) "e"
127.0.0.1:6379> lrange list0 0 -1
1) "c"
2) "b"
3) "a"
4) "d"
127.0.0.1:6379> rpoplpush list0 list0
"d"
127.0.0.1:6379> lrange list0 0 -1
1) "d"
2) "c"
3) "b"
4) "a"
127.0.0.1:6379> llen list0
(integer) 4
3.4.5 Redis常用命令讲解之Set
- SADD
- SREM
- SMEMBERS
- SISMEMBER
- SDIFF(差集)
- SINTER(并集)
- SUNION(交集)
- SCARD(元素个数)
127.0.0.1:6379> sadd letters a b
(integer) 2
127.0.0.1:6379> SMEMBERS letters
1) "b"
2) "a"
127.0.0.1:6379> SISMEMBER letters a
(integer) 1
127.0.0.1:6379> sadd setA 1 2 3
(integer) 3
127.0.0.1:6379> sadd setB 2 3 4
(integer) 3
127.0.0.1:6379> sdiff setA setB
1) "1"
127.0.0.1:6379> SINTER seta setb
(empty list or set)
127.0.0.1:6379> SINTER setA setB
1) "2"
2) "3"
127.0.0.1:6379> SUNION setA setB
1) "1"
2) "2"
3) "3"
4) "4"
127.0.0.1:6379> scard setA
(integer) 3
3.4.6 Redis常用命令讲解之Sorted Set
- ZADD(添加元素)
- ZSCORE(获得某个元素)
- ZRANGE(按照次序给出存在的元素)
- ZRANGEBYSCORE(给出给定range里的所有元素,左右都闭)
- ZINCRBY(增加一个元素分数)
127.0.0.1:6379> ZADD scoreboard 10 x 20 y 30 z 15 a
(integer) 4
127.0.0.1:6379> zscore scoreboard y
"20"
127.0.0.1:6379> zrange scoreboard 2 3
1) "y"
2) "z"
127.0.0.1:6379> ZRANGEBYSCORE scoreboard 15 25
1) "a"
2) "y"
127.0.0.1:6379> ZINCRBY scoreboard 30 x
"40"
4. Python与Redis
4.1 Redis Python客户端介绍
推荐使用redis-py
-
Getting Started
>>> import redis >>> r = redis.StrictRedis(host="localhost", port=6379,db=0) >>> r.set('foo','bar') True >>> r.get('foo') 'bar'
4.2 消息队列的插入与取出
4.2.1 基于 redis-py 生产者开发
-
每2秒随机生成一个用户名插入到队列中
-
LPUSH
# producer1.py import redis import names import time r = redis.StrictRedis(host='localhost', port=6379, db=0) while True: time.sleep(2) name = names.get_full_name() x = r.lpush('names',name) print(x,name)
4.2.2 基于 redis-py 消费者开发
-
将队列中的用户名按照插入顺序取出并打印到屏幕上
-
BRPOP
# consumer1.py import redis r = redis.StrictRedis(host='localhost', port=6379, db=0) def consume(key): while(True): value = r.brpop(key) yield value for v in consume('names'): print(v)
4.3 基于频道的发布与订阅
4.3.1 基于 redis-py 生产者开发
-
每2秒随机生成一个用户名发布到频道中
-
PUBLISH
# producer2.py import redis import names import time r = redis.StrictRedis(host='localhost', port=6379, db=0) while True: time.sleep(2) name = names.get_full_name() x = r.publish('names',name) print(x,name)
4.3.2 基于 redis-py 消费者开发
-
订阅发布用户名的频道,有新的消息时打印到屏幕上
-
SUBSCRIBE
# consumer2.py import redis r = redis.StrictRedis(host='localhost', port=6379, db=0) ps = r.pubsub() ps.subscribe('names') for item in ps.listen(): print(item)
5. Kafka
5.1 Kafka简介与应用场景
-
Kafka简介-关键词
- 磁盘消息队列
- 高性能
- 分布式
- Zookeeper
- 实时流处理
- 重复消费
-
Kafka简介--API
- 生产者API
- 消费者API
- 流处理器API
- 连接器API
-
Kafka简介--生产者
- 异步通信,所有网路请求异步发送
- 批量发送,通过设置batch size或者timeout一次发送多个消息
- 线程安全,多个线程之间可以共享单个生产者实例
- 负载均衡,采用内部默认机制或者自定义负载均衡策略
- 返回结果,返回消息的topic,offset等元数据
-
Kafka简介--消费者
- 统一API,不在区分high-level consumer API和low-level consumer API
- 多次消费,不会删除已消费的信息,允许重复消费
- 负载均衡,基于partition和consumer group自动负载均衡
- 流量控制,允许开发者控制每次请求返回消息的条数
-
Kafka简介--安全
- 连接认证,连接到服务器的生产者和消费者客户端使用SSL或者SASL进行验证
- 权限管理,broker连接Zookeeper进行权限管理
- 加密传输,数据传输进行加密
- 授权管理,客户端读、写操作可以进行授权管理
-
Kafka简介--连接器
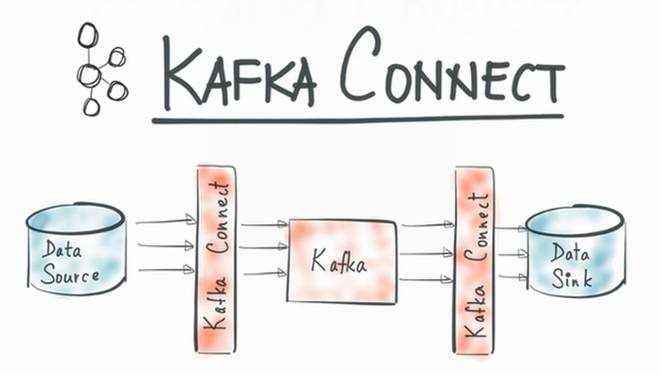
5.2 Kafka常见应用场景
- 消息服务器
- 网站活动跟踪
- 实时数据流聚合
- 日志聚合
5.3 Kafka安装与简单用例
5.3.1 安装
-
下载并且解压缩kafka安装包 这里选择当前最近的2.3.0版本
$ wget http://apache.website-solution.net/kafka/2.3.0/kafka-2.3.0-src.tgz $ tar -xzf kafka_2.12-2.3.0.tgz $ cd kafka_2.12-2.3.0 -
安装Gradle和Zookeeper,为了方便管理 这里统一使用
$ brew install gradle $ brew install zookeeper
5.3.2 启动服务
-
启动Zookeeper
$ bin/zookeeper-server-start.sh config/zookeeper.properties 如果是使用homebrew 直接使用下面两条命令即可 $ zkServer $ zkCli -
启动kafka
$ bin/kafka-server-start.sh config/server.properties
5.3.3 创建一个Topic
-
创建一个测试用Topic
$ bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test -
查看当前已经创建的测试Topic
$ bin/kafka-topics.sh --list --bootstrap-server localhost:9092 test1输出test1 说明创建成功
5.3.4 消息的生产与消费
-
通过producer产生消息
$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test >this is message one >this is message two -
通过comsumer拿到所有当前消息
$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning this is message one this is message two成功输出输入的消息
5.4 Kafka的配置
5.4.1 Kafka服务器配置文件
-
配置文件位于config/server.properties下
-
通过如下命令将配置文件导出至broker.properties中
$ grep '^[^#]' server.properties > broker.properties -
查看broker.properties中去除了注释的内容
broker.id=0 num.network.threads=3 num.io.threads=8 socket.send.buffer.bytes=102400 socket.receive.buffer.bytes=102400 socket.request.max.bytes=104857600 log.dirs=/tmp/kafka-logs num.partitions=1 num.recovery.threads.per.data.dir=1 offsets.topic.replication.factor=1 transaction.state.log.replication.factor=1 transaction.state.log.min.isr=1 log.retention.hours=168 log.segment.bytes=1073741824 log.retention.check.interval.ms=300000 zookeeper.connect=localhost:2181 zookeeper.connection.timeout.ms=6000 group.initial.rebalance.delay.ms=0
5.4.2 Kafka默认配置项
加粗的为重要配置
-
Disk IO
- num.io.threads = 8 设置broker处理磁盘IO的线程数
- num.partitions = 1 设置每个topic的分区个数
- num.recovery.threads.per.data.dir = 1 配置每个数据恢复时的线程数
- log.dirs = /tmp/kafka-logs kafka数据的存放目录
- log.retention.hours = 168 消息的存储时间 单位是小时
- log.segment.bytes = 1073741824 topic的partition是以segment的形式存储的
- log.retention.check.interval.ms=300000 定时检查文件大小
-
Network
- num.network.threads = 3 设置broker处理网络请求的最大线程数 一般可设置为CPU的核数
- socket.send.buffer.bytes=102400 socket发送缓冲区的大小;-1即为操作系统默认值
- socket.receive.buffer.bytes=102400 接受缓冲区;-1为默认值
- socket.request.max.bytes=104857600 每一个socket的最大字节数
-
Cluster
-
zookeeper.connect=localhost:2181 zookeeper的集群地址;值可以有多个,中间用逗号分隔
-
zookeeper.connection.timeout.ms=6000 连接的超时时间
-
broker.id=0 broker在集群中的唯一标识;如果没有,zookeeper从1001开始递增
-
5.5 Kafka相关概念
5.5.1 常见概念--集群
- Cluster:集群
- Broker:每个服务器都是一个Broker
- Producer:生产者
- Consumer:消费者
- Consumer Group:实现topic广播的手段
5.5.2 常见概念--消息
- Record:每一条消息
- Topic:每一个消息都会有一个Topic
- Partition:每个Topic包含一个或者多个Partition
- Segment:每个Partition包含一个或者多个Segment
- Offset:Partition中每个消息都有的序列号,可以唯一标识一条消息
- Replication:副本;kafka支持以Partition为单位对消息进行备份
- Leader:所有读写请求都由Leader来处理
5.5.3 常见概念--Topic
-
Topic可以被看做是一个队列
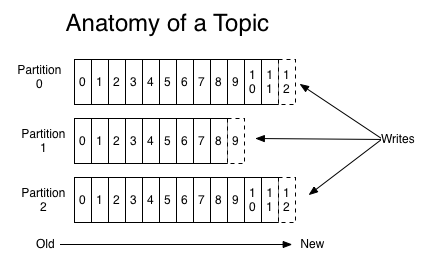
5.5.4 常见概念--Partition
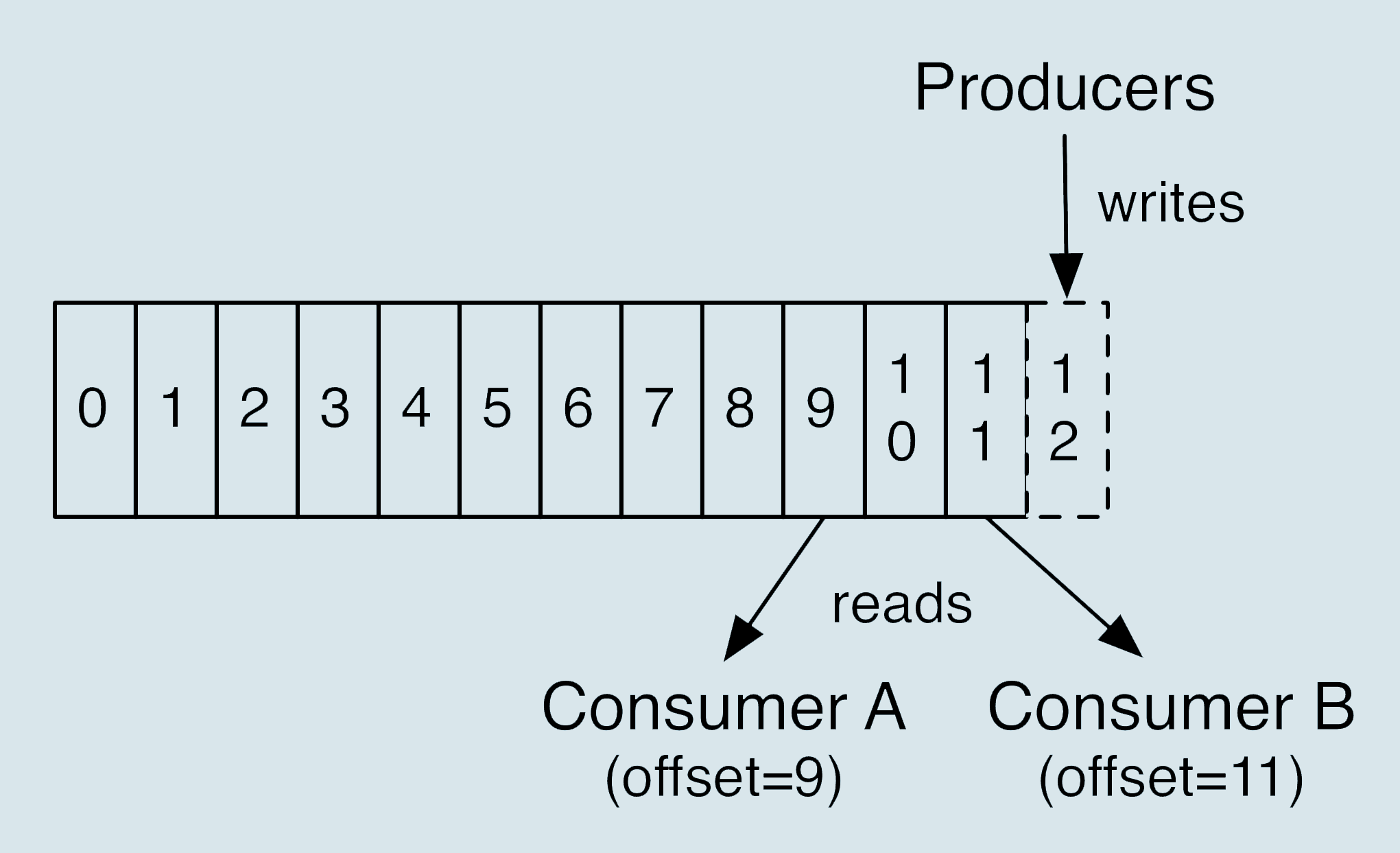
5.5.5 常见概念--Segment
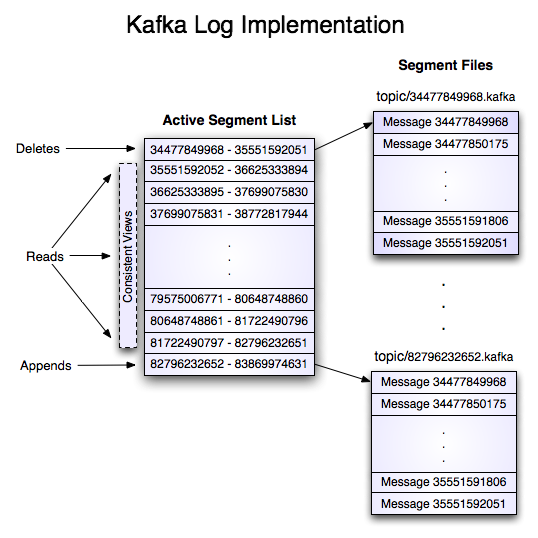
5.5.6 常见概念--集群
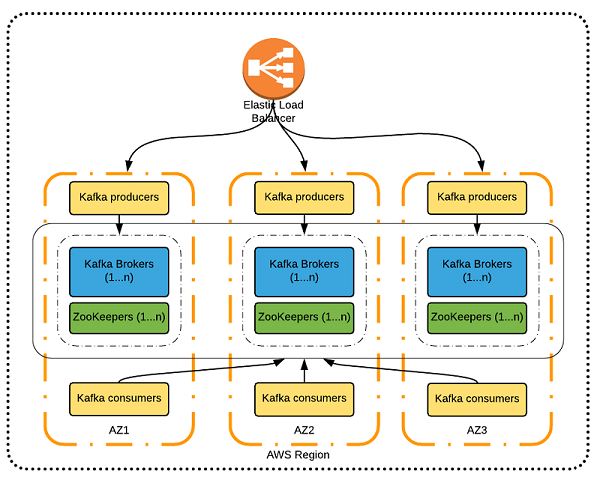
6. Python与Kafka
- 由于有很多python库都可以使用kafka
- 知名的有kafka-python;pykafka;faust;这里使用kafka-python
使用pip安装
pip install kafka-python
-
创建kafkaProducer.py
from kafka import KafkaProducer import names producer = KafkaProducer() for _ in range(10): name = names.get_full_name() future = producer.send('test', bytes(name,'utf-8')) result = future.get(60) print(result) -
创建kafkaConsumer.py
from kafka import KafkaConsumer consumer = KafkaConsumer('test',group_id='test01') for msg in consumer: print(msg) -
进行数据的产生与消费
$ python kafkaProducer.py RecordMetadata(topic='test', partition=0, topic_partition=TopicPartition(topic='test', partition=0), offset=14, timestamp=1571317704074, checksum=None, serialized_key_size=-1, serialized_value_size=15, serialized_header_size=-1) RecordMetadata(topic='test', partition=0, topic_partition=TopicPartition(topic='test', partition=0), offset=15, timestamp=1571317704182, checksum=None, serialized_key_size=-1, serialized_value_size=12, serialized_header_size=-1) ...$ python kafkaConsumer.py ConsumerRecord(topic='test', partition=0, offset=14, timestamp=1571317704074, timestamp_type=0, key=None, value=b'Margaret Medina', headers=[], checksum=None, serialized_key_size=-1, serialized_value_size=15, serialized_header_size=-1) ConsumerRecord(topic='test', partition=0, offset=15, timestamp=1571317704182, timestamp_type=0, key=None, value=b'Mark Mccarty', headers=[], checksum=None, serialized_key_size=-1, serialized_value_size=12, serialized_header_size=-1) ...可以看到,通过Producer产生的数据已经被Consumer成功拿到。
7. 框架整合
7.1 采集日志
7.1.1 日志采集方案介绍
- flume
- rsyslog
- heka
- logstash
7.1.2 nginx访问日志格式配置
-
自定义日志格式
-
直接输出json
log_format json '{"@timestamp":"$time_iso8601",' '"host":"$server_addr",' '"clientip":"$remote_addr",' '"size":$body_bytes_sent,' '"responsetime":$request_time,' '"upstreamtime":"$upstream_response_time",' '"upstreamhost":"$upstream_addr",' '"http_host":"$host",' '"url":"$url",' '"xff":"$http_x_forwarded_for",' '"refer":"$http_referer",' '"agent":"$http_user_agent",' '"status":"$status"}'; asscess_log /tmp/nginx/access.log json; -
可以看到nginx的access日志就是json格式的了
7.2 logstash配置
- logstash配置主要分为以下三个部分
- input
- filter
- output
7.2.1 kafka插件
-
配置logstash output kafka插件
input { file { path => "/pot/openresty/nginx/logs/access.log" codec => json } } filter { # 对useragent进行预处理 useragent { source => "agent" target => "user_agent" remove_field => "agent" } # 对ip地址的地区进行预处理 geoip { source => "clientip" target => "geoip" } } output { # debug用 stdout { codec => rubydebug } # logstash output kafka插件 kafka { codec => json topic_id => "nginx" # kafka对外地址 bootstrap_servers => "localhost:9092" } }
7.3 启动日志
依次运行一下应用
- nginx
- logstash
- kafka
- Zookeeper